







Runtime Systems and Tools:
Topology Aware Mapping
Introduction
Petascale machines with hundreds of thousands of cores are being built. These machines have varying interconnect topologies and large network diameters. Computation is cheap and communication on the network is becoming the bottleneck for scaling of parallel applications. Network contention, specifically, is becoming an increasingly important factor affecting overall performance. The broad goal of this research is performance optimization of parallel applications through reduction of network contention.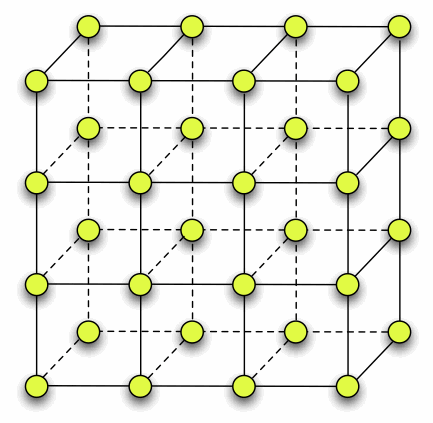 Most parallel applications have a certain communication topology. Mapping of tasks in a parallel application based on their communication graph, to the physical processors on a machine can potentially lead to performance improvements. We have developed an automatic mapping framework and implemented a mapping library to map the communication graph for an application on to the interconnect topology of a machine while trying to localize communication.
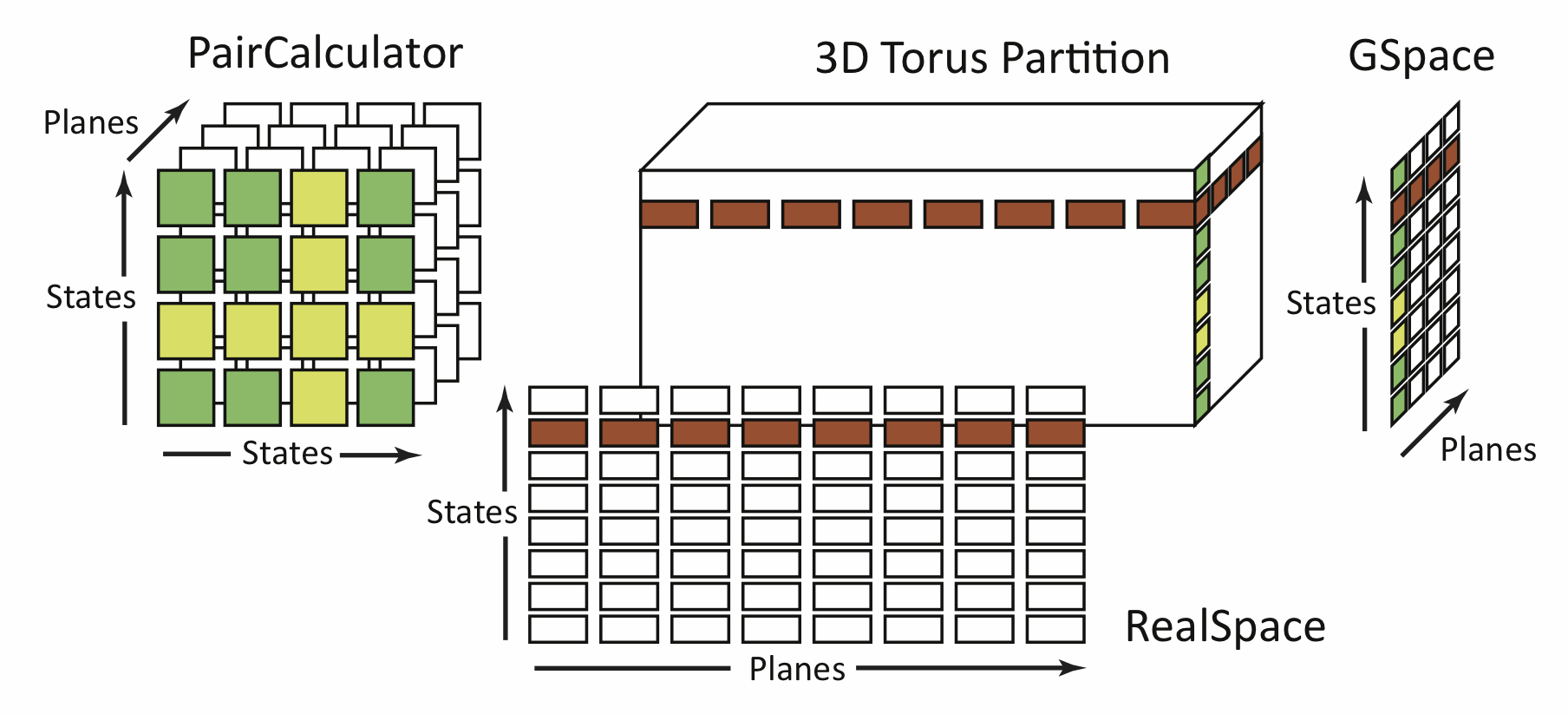
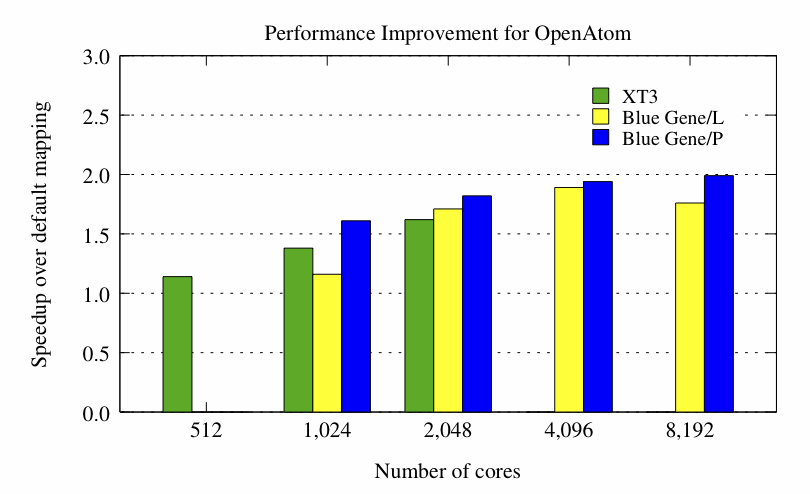
Most parallel applications have a certain communication topology. Mapping of tasks in a parallel application based on their communication graph, to the physical processors on a machine can potentially lead to performance improvements. We have developed an automatic mapping framework and implemented a mapping library to map the communication graph for an application on to the interconnect topology of a machine while trying to localize communication.A parallel quantum chemistry application, OpenAtom, runs twice as fast when its objects are mapped in a topology aware fashion on various machines (see figures below). NAMD, a molecular dynamics applications also sees performance improvements of 10-15% at the scaling end. Building on these ideas, we have developed algorithms and techniques for automatic mapping of parallel applications to relieve the application developers of this burden. We use the hop-bytes metric for the evaluation of mapping algorithms and suggest that it is a better metric than the previously used maximum dilation metric. The main focus of this research is on developing topology aware mapping algorithms for parallel applications with regular and irregular communication patterns. The automatic mapping framework is a suite of such algorithms with capabilities to choose the best mapping for a problem with a given communication graph.
Software available for download
Contributions of this research
Our work is among the first to discuss the effects of contention on Cray and IBM machines and to compare across multiple architectures. Contrary to popular belief that Cray machines do not stand to benefit from topology mapping, this research proves otherwise and provides detailed methods and results for performance improvements from topology mapping on them. Another contribution of this work is an API for topology discovery which works on both Cray and IBM machines.We believe that the set of MPI benchmarks we have developed for quantifying message latencies would be useful for the HPC community to assess latencies on a supercomputer and to determine the message sizes for which number of hops makes a significant difference. The effective bandwidth benchmark in the HPC Challenge benchmark suite measures the total bandwidth available on a system but does not analyze the effects of distance or contention on message latencies. Results from MPI benchmarks re-establish the importance of mapping for the current supercomputers.
Our experience in developing mapping algorithms for production codes and insights discussed in this work will be useful to individual application writers trying to scale their codes to large supercomputers. We believe that the automatic mapping framework is applicable to a wide variety of communication scenarios and will relieve the application writers from the burden of finding good mapping solutions for their codes. Application developers can use this framework for mapping of their applications without any changes to their code base. Unlike most of the previous work, this research handles both cardinality and topological variations in the graphs. The framework provides scalable and fast, runtime solutions. Therefore, it will be useful to a large body of applications running on large parallel machines.
There has not been much research on mapping of unstructured mesh applications for performance optimizations and this research takes up at that task. We have also started developing scalable techniques for distributed load balancing in an effort to move away from centralized mapping decision algorithms.
People
Papers/Talks
17-02
2017
[Paper]
[Paper]
Automatic topology mapping of diverse large-scale parallel applications [ICS 2017]
16-21
2016
[Poster]
[Poster]
ACM SRC: Mapping Applications on Irregular Allocations [SC 2016]
{kind=link}
16-11
2016
[Paper]
[Paper]
Evaluating HPC Networks via Simulation of Parallel Workloads [SC 2016]
16-05
2016
[Paper]
[Paper]
OpenAtom: Scalable Ab-Initio Molecular Dynamics with Diverse Capability [ISC 2016]
16-04
2016
[Paper]
[Paper]
Analyzing network health and congestion in dragonfly-based systems [IPDPS 2016]
16-02
2016
[PhD Thesis]
[PhD Thesis]
Optimization of Communication Intensive Applications on HPC Networks [Thesis 2016]
15-03
2015
[Paper]
[Paper]
Identifying the Culprits behind Network Congestion [IPDPS 2015]
14-40
2014
[Talk]
[Talk]
Maximizing Throughput on a Dragonfly Network [SC 2014]
14-14
2014
[Paper]
[Paper]
Optimizing the performance of parallel applications on a 5D torus via task mapping [HiPC 2014]
14-04
2014
[Paper]
[Paper]
Maximizing Throughput on a Dragonfly Network [SC 2014]
13-18
2013
[Paper]
[Paper]
Predicting Application Performance using Supervised Learning on Communication Features [SC 2013]
13-13
2013
[Talk]
[Talk]
Predicting Application Performance using Supervised Learning on Communication Features [Lawrence Livermore Talk 2013]
11-47
2011
[Talk]
[Talk]
Avoiding Hot-Spots on Two-Level Direct Networks [SC 2011]
11-36
2011
[Talk]
[Talk]
Heuristic-based Techniques for Mapping Irregular Communication Graphs to Mesh Topologies [ESCAPE 2011]
11-22
2011
[Paper]
[Paper]
Improving Communication Performance in Dense Linear Algebra via Topology Aware Collectives [SC 2011]
11-21
2011
[Paper]
[Paper]
Avoiding Hot-Spots on Two-Level Direct Networks [SC 2011]
11-12
2011
[Paper]
[Paper]
Heuristic-Based Techniques for Mapping Irregular Communication Graphs to Mesh Topologies [ESCAPE 2011]
11-02
2011
[Paper]
[Paper]
Topology Aware Task Mapping [Encyclopedia of Parallel Computing 2011]
10-18
2010
[Paper]
[Paper]
Automated Mapping of Regular Communication Graphs on Mesh Interconnects [HiPC 2010]
10-17
2010
[PhD Thesis]
[PhD Thesis]
Automating Topology Aware Mapping for Supercomputers [Thesis 2010]
10-07
2010
[Paper]
[Paper]
Automated Mapping of Structured Communication Graphs onto Mesh Interconnects [CS Res. & Tech. Report 2010]
10-04
2010
[Paper]
[Paper]
Optimizing Communication for Charm++ Applications by Reducing Network Contention [Concurrency and Computation: Practice and Experience 2010]
09-16
2009
[Poster]
[Poster]
Topology Aware Task Mapping Techniques: An API and Case Study [PPoPP 2009]
09-07
2009
[Paper]
[Paper]
Quantifying Network Contention on Large Parallel Machines [PPL 2009]
09-04
2009
[Paper]
[Paper]
A Pattern Language for Topology Aware Mapping [ParaPLoP 2009]
09-02
2009
[Paper]
[Paper]
Dynamic Topology Aware Load Balancing Algorithms for Molecular Dynamics Applications [ICS 2009]
09-01
2009
[Paper]
[Paper]
An Evaluative Study on the Effect of Contention on Message Latencies in Large Supercomputers [LSPP 2009]
08-18
2008
[Poster]
[Poster]
Effects of Contention on Message Latencies in Large Supercomputers [SC 2008]
08-17
2008
[Poster]
[Poster]
Automatic Topology-Aware Task Mapping for Parallel Applications Running on Large Parallel Machines [IPDPS 2008]
08-10
2009
[Paper]
[Paper]
A Case Study of Communication Optimizations on 3D Mesh Interconnects [Euro-Par 2009]
08-07
2008
[Paper]
[Paper]
Benefits of Topology Aware Mapping for Mesh Interconnects [PPL 2008]
08-02
2008
[Paper]
[Paper]
Application-specific Topology-aware Mapping for Three Dimensional Topologies [LSPP 2008]
07-12
2007
[MS Thesis]
[MS Thesis]
Application-specific Topology-aware Mapping and Load Balancing for three-dimensional Torus Topologies [Thesis 2007]
07-03
2007
[Paper]
[Paper]
Fine Grained Parallelization of the Car-Parrinello ab initio MD Method on Blue Gene/L [IBM Journal of Research and Development 2007]
05-18
2006
[Paper]
[Paper]
Topology-Aware Task Mapping for Reducing Communication Contention on Large Parallel Machines [IPDPS 2006]
05-09
2005
[MS Thesis]
[MS Thesis]
Low Diameter Regular Graph as a Network Topology in Direct and Hybrid Interconnection Networks [Thesis 2005]
05-07
2005
[MS Thesis]
[MS Thesis]
Strategies for topology-aware task mapping and for rebalancing with bounded migrations [Thesis 2005]