







Grid, Clusters, and Clouds:
Faucets - Shared Computing Power
The Faucets project was carried out in the context of grids in early-mid 2000s. Some of the research that we carried out under Faucets projects is becoming increasingly relevant today. E.g. malleable jobs and market-driven pricing are gaining importance in HPC in cloud scenarios.
As scientists write more and more parallel applications that require large amounts of computational resources, large parallel machines will become more commonplace. However, these machines are often prohibitively expensive for any single user and so must be shared by many users. Furthermore, the machines tend to go through periods of low and high utilization. During the periods of high utilization, users might not be able to get enough computational resources to get results in time to meet a deadline. During the periods of low utilization, the computational power sits idle while someone across the country may be wishing they had just a few more nodes so that they could run their program.
The Faucets system addresses this second problem by allowing subscribers to share their resources. In the Faucets system, computational power is viewed as a utility. A supercomputer produces the utility and the users consume it. When a user finds the cluster they normally use is not providing enough of the utility, they can "borrow" some from another subscribing cluster which is currently being underused. In the future, a user of the second cluster might run an application on the first when the situation is reversed. Faucets provides both the technical framework and economic model to facilitate the discovery, distribution, and pricing of computational power.
As part of our Faucets project, we present several complementary ideas and their implementation that improve the efficiency of parallel servers in the Grid environment:
The Faucets project recently received funding through the NCSA/UIUC Faculty Fellows Program. Read the official announcement.
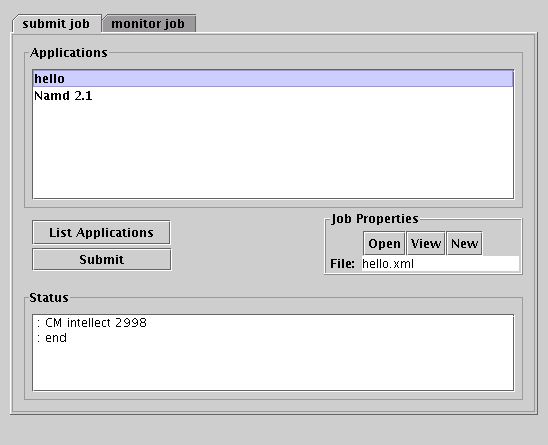
The Faucets client interface.
As scientists write more and more parallel applications that require large amounts of computational resources, large parallel machines will become more commonplace. However, these machines are often prohibitively expensive for any single user and so must be shared by many users. Furthermore, the machines tend to go through periods of low and high utilization. During the periods of high utilization, users might not be able to get enough computational resources to get results in time to meet a deadline. During the periods of low utilization, the computational power sits idle while someone across the country may be wishing they had just a few more nodes so that they could run their program.
The Faucets system addresses this second problem by allowing subscribers to share their resources. In the Faucets system, computational power is viewed as a utility. A supercomputer produces the utility and the users consume it. When a user finds the cluster they normally use is not providing enough of the utility, they can "borrow" some from another subscribing cluster which is currently being underused. In the future, a user of the second cluster might run an application on the first when the situation is reversed. Faucets provides both the technical framework and economic model to facilitate the discovery, distribution, and pricing of computational power.
As part of our Faucets project, we present several complementary ideas and their implementation that improve the efficiency of parallel servers in the Grid environment:
- Bartering: a system which permits cluster maintainers to exchange computational power with each other. Jobs are submitted to the Faucets system with a Quality of Service requirement and subscribing clusters return bids; the best bid which meets all criteria is selected. When an application is successfully run by the bidding cluster, it is awarded bartering units which its users can later trade for the use of resources on other subscribing clusters.
- Adaptive Jobs: a system that supports adaptive jobs (also known as malleable and/or evolving jobs) that can shrink and expand to a variable number of processors at run-time, and an Adaptive Job Scheduler for timeshared parallel machines that exploits this ability.
- On-Demand Computing: users can get the resources they need when they need them. Furthermore, they can specify that their jobs need to be run immediately. High priority jobs can preempt low priority jobs so that computational resources are used as efficiently as possible.
- Scheduler: we provide a scheduling system for clusters which can either be used in conjunction with Faucets or as a stand-alone scheduler.
Technical Overview of the Faucets System Cluster Scheduler Manual
News
October 19, 2005: The source code available for download through this page has been updated to match the version in CVS. This version addresses some bug fixed and adds some more options to the cluster scheduler.The Faucets project recently received funding through the NCSA/UIUC Faculty Fellows Program. Read the official announcement.
People
Papers/Talks
04-09
2004
[Paper]
[Paper]
Faucets: Efficient Resource Allocation on the Computational Grid [ICPP 2004]
03-14
2003
[Paper]
[Paper]
Analyzing Bidding Strategies for Schedulers in a Simulated Multiple-Cluster Market Driven Environment [Thesis 2003]
03-01
2003
[Paper]
[Paper]
Faucets: Efficient Resource Allocation on the Computational Grid [PPL Technical Report 2003]
02-01
2002
[Paper]
[Paper]
A Malleable-Job System for Timeshared Parallel Machines [CCGrid 2002]
01-06
2001
[MS Thesis]
[MS Thesis]
An Adaptive Job Scheduler for Timeshared Parallel Machines [Thesis 2001]
00-02
2000
[Paper]
[Paper]
An Adaptive Job Scheduler for Timeshared Parallel Machines [PPL Technical Report 2000]