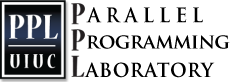









Jonathan Lifflander
PhD Students
jliffl2 at illinois.edu
Profile
Jonathan Lifflander is a 6th year computer science PhD candidate at UIUC (University of Illinois Urbana-Champaign) researching parallel computing, systems, and HPC in the Parallel Programming Laboratory (PPL), advised by Laxmikant (Sanjay) V. Kale. In 2013, he won the George Michael High Performance Computing award for research excellence and academic progress. At CLUSTER'14, he won the best student paper award for his work in partial-order dependencies for fault tolerance.
He has first-author full publications in the following venues: SC'14, CLUSTER'14, PLDI'13, PPoPP'13, HPDC'12, IPDPS'12.
Please visit my personal research website for up-to-date information and an online CV.
He has first-author full publications in the following venues: SC'14, CLUSTER'14, PLDI'13, PPoPP'13, HPDC'12, IPDPS'12.
Please visit my personal research website for up-to-date information and an online CV.
Research Areas
- Performance-analysis-based Introspective Control System to Tune Applications and Runtime
- Dense LU Factorization
- Dynamic Load Balancing
- Dagger and Structured Dagger
- AMR - Adaptive Mesh Refinement Framework
- Parallel Performance Analysis, Visualization and Optimization
- Fault Tolerance Support
- Parallel Algorithms and Applications
Papers
15-19
2015
[Paper]
[Paper]
Recovering Logical Structure from Charm++ Event Traces [SC 2015]
14-24
2014
[Paper]
[Paper]
Optimizing Data Locality for Fork/Join Programs Using Constrained Work Stealing [SC 2014]
14-21
2014
[Paper]
[Paper]
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance [Cluster 2014]
14-12
2014
[Paper]
[Paper]
PICS: A Performance-Analysis-Based Introspective Control System to Steer Parallel Applications [ROSS 2014]
13-44
2013
[Paper]
[Paper]
Parallel Science and Engineering Applications: The Charm++ Approach: Chapter 3: Tools for Debugging and Performance Analysis [Book 2013]
13-36
2012
[Paper]
[Paper]
Controlling Concurrency and Expressing Synchronization in Charm++ Programs [Concurrent Objects and Beyond 2012]
13-04
2013
[Paper]
[Paper]
Steal Tree: Low-Overhead Tracing of Work Stealing Schedulers [PLDI 2013]
12-47
2012
[Paper]
[Paper]
Migratable Objects + Active Messages + Adaptive Runtime = Productivity + Performance: A Submission to the 2012 HPC Class II Challenge [SC 2012]
12-46
2013
[Paper]
[Paper]
Adoption Protocols for Fanout-Optimal Fault-Tolerant Termination Detection [PPoPP 2013]
12-35
2012
[Paper]
[Paper]
Scalable Algorithms for Distributed-Memory Adaptive Mesh Refinement [SBAC-PAD 2012]
12-11
2012
[Paper]
[Paper]
Work Stealing and Persistence-based Load Balancers for Iterative Overdecomposed Applications [HPDC 2012]
12-06
2012
[Paper]
[Paper]
Dynamic Scheduling for Work Agglomeration on Heterogeneous Clusters [Workshop on Multicore and GPU Programming Models, Languages and Compilers at IPDPS 2012]
12-02
2012
[Paper]
[Paper]
A Parallel Algorithm for 3-D Particle Tracking and Lagrangian Trajectory Reconstruction [Journal of Measurement Science and Technology 2012]
11-51
2012
[Paper]
[Paper]
Mapping Dense LU Factorization on Multicore Supercomputer Nodes [IPDPS 2012]
11-49
2011
[Paper]
[Paper]
Charm++ for Productivity and Performance: A Submission to the 2011 HPC Class II Challenge [SC 2011]
11-34
2011
[Paper]
[Paper]
Exploring Partial Synchrony in an Asynchronous Environment Using Dense LU [PPL Technical Report 2011]
10-19
2010
[Paper]
[Paper]
A Study of Memory-Aware Scheduling in Message Driven Parallel Programs [HiPC 2010]
10-05
2010
[Paper]
[Paper]
A Study of Memory-Aware Scheduling in Message Driven Parallel Programs [PPL Technical Report 2010]
Talks/Posters
14-36
2014
[Talk]
[Talk]
Optimizing Data Locality for Fork/Join Programs Using Constrained Work Stealing [SC 2014]
14-31
2014
[Talk]
[Talk]
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance [Cluster 2014]
13-35
2013
[Poster]
[Poster]
Steal Tree: Low-Overhead Tracing of Work Stealing Schedulers [PLDI 2013]
{kind=link}
13-34
2013
[Talk]
[Talk]
Projections: Scalable Performance Analysis and Visualization [VAPLS 2013]
13-12
2013
[Talk]
[Talk]
Steal Tree: Low-Overhead Tracing of Work Stealing Schedulers [PLDI 2013]
13-06
2013
[Talk]
[Talk]
Adoption Protocols for Fanout-Optimal Fault-Tolerant Termination Detection [PPoPP 2013]
13-03
2013
[Poster]
[Poster]
Charm++: Migratable Objects + Active Messages + Adaptive Runtime = Productivity + Performance [PSAAP Site-visit 2013]
{kind=link}
13-02
2013
[Poster]
[Poster]
Scalable Algorithms for Distributed-Memory Adaptive Mesh Refinement [PSAAP Site-visit 2013]
12-52
2012
[Poster]
[Poster]
Work Stealing and Persistence-based Load Balancers for Iterative Overdecomposed Applications [HPDC 2012]
12-51
2012
[Talk]
[Talk]
Scalable Algorithms for Distributed-Memory Adaptive Mesh Refinement [SBAC-PAD 2012]
12-25
2012
[Talk]
[Talk]
Work Stealing and Persistence-based Load Balancers for Iterative Overdecomposed Applications [HPDC 2012]
12-24
2012
[Talk]
[Talk]
Dynamic Scheduling for Work Agglomeration on Heterogeneous Clusters [Workshop on Multicore and GPU Programming Models, Languages and Compilers at IPDPS 2012]
12-23
2012
[Talk]
[Talk]
Mapping Dense LU Factorization on Multicore Supercomputer Nodes [IPDPS 2012]
12-16
2012
[Talk]
[Talk]
Charm++ Tutorial for UIUC SIAM [Charm++ Workshop 2012]